На вкладке "Наборы параметров" задаются параметры, необходимые для построения блочной модели.
Одновременно может быть задано множество наборов параметров.
Например в одном наборе параметров задается вычисление содержаний золота, в другом - вычисление содержаний серебра и т.д.
Для разных частей месторождения могут быть свои, отличающиеся от других, наборы параметров.
Процесс построения модели можно рассматривать как последовательное выполнение построений для каждого из заданных наборов параметров.
Наборы параметров привлекаются для построения модели в том порядке, в котором они перечислены в списке наборов параметров.
Если для блочной модели еще не задан ни один набор параметров, то большинство элементов диалога будут неактивными, т.к. нет ни одного набора параметров :
После нажатия на кнопку ![]() произойдет добавление в список нового набора параметров с названием "Набор параметров 1":
произойдет добавление в список нового набора параметров с названием "Набор параметров 1":
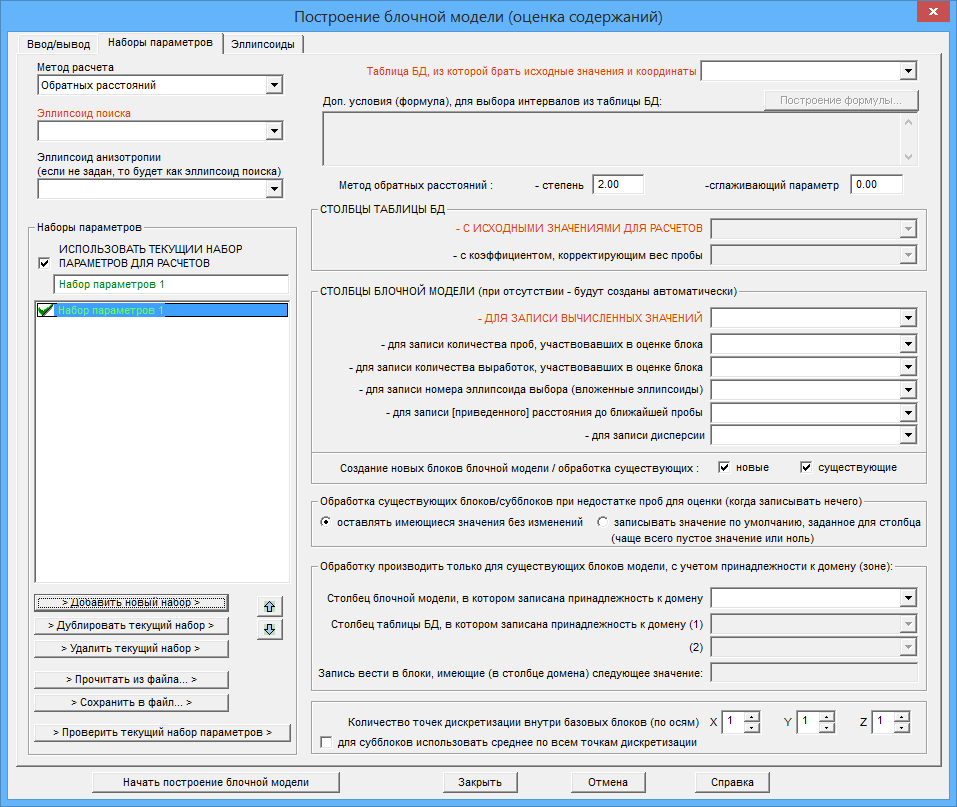
Метод расчета
1. Обратных расстояний (в заданной степени). В западных программах для этого метода используется термин Inverse Power of Distance (IPD). Также можно встретить термины Inverse Distance to a Power и Inverse Distance Weighting (IDW).
2. Ближайшего соседа. В западной терминологии - Nearest Neighbour.
Эллипсоид поиска
Из списка выбирается эллипсоид, который использовать в текущем наборе параметров в качестве эллипсоида поиска.
Список эллипсоидов формируется в этом же диалоге, на вкладке "Эллипсоиды".
Эллипсоид поиска используется при выборе проб, которые участвуют в расчетах для каждого блока.
Эллипсоид анизотропии
Из списка выбирается эллипсоид, который использовать в текущем наборе параметров.
Список эллипсоидов формируется в этом же диалоге, на вкладке "Эллипсоиды".
Эллипсоид анизотропии используется при вычислениях весовых коэффициентов для каждой из проб, участвующих в расчетах.
В отличие от эллипсоида поиска, для эллипсоида анизотропии используются не все параметры, которые имеются на вкладке "Эллипсоиды", а только две группы параметров:
1. Длины полуосей эллипсоида.
Если эллипсоид используется только как эллипсоид анизотропии, то для него можно задать не абсолютные длины полуосей а относительные числа, определяющие соотношения длин полуосей.
Например, длину малой полуоси задать равной 1.0, длину средней полуоси - 2.0, а длину главной полуоси - 4.0.
2. Углы поворота, определяющие ориентацию осей эллипсоида.
Остальные параметры, имеющиеся на вкладке "Эллипсоида" необходимы только при использовании эллипсоида как эллипсоида поиска.
Нередко один и тот же эллипсоид используется и как эллипсоид поиска и как эллипсоид анизотропии (хотя это далеко не всегда правильно).
В таких случаях достаточно задать только эллипсоид поиска, а управляющий элемент "Эллипсоид анизотропии" можно оставить пустым.
Наборы параметров
Для блочной модели можно задавать много наборов параметров.
Фактически процесс построения блочной модели состоит из последовательно выполняемых расчетов по каждому (активному) набору параметров.
Наборы параметров используются в том порядке, в котором они перечислены в списке наборов параметров.
ИСПОЛЬЗОВАТЬ ТЕКУЩИЙ НАБОР ПАРАМЕТРОВ ДЛЯ РАСЧЕТА - если отмечено, то набор параметров будет принимать участие в расчете (активный набор параметров), если не отмечено - то набор параметров в процессе расчетов будет пропускаться.
Включение / выключение этого признака можно также производить при помощи при установке курсора на соответствующую строку в списке с наборами параметров.
Названия наборов параметров, предназначенных для расчетов в списке выводятся зеленым цветом, а временно неактивные наборы параметров - серым цветом.
Текущий набор параметров подсвечивается в списке, а его название дублируется в редактируемом управляющем элементе, находящемся выше списка наборов параметров.
Редактирование названия набора параметров в этом элементе диалога приводит к соответствующему изменению названия в списке.
Для работы со списком наборов параметров предусмотрены следующие кнопки:
![]() - добавление в список нового пустого набора параметров с названием "Набор параметров N", где N - номер набора параметров.
- добавление в список нового пустого набора параметров с названием "Набор параметров N", где N - номер набора параметров.
![]() - добавление в список копии текущего набора параметров с названием, повторяющим название текущего набора параметров и добавлением в конце названия номера копии, т.к. названия наборов параметров не могут быть одинаковыми.
- добавление в список копии текущего набора параметров с названием, повторяющим название текущего набора параметров и добавлением в конце названия номера копии, т.к. названия наборов параметров не могут быть одинаковыми.
![]() - удаление текущего набора параметров из списка.
- удаление текущего набора параметров из списка.
![]() - чтение из файла с расширением *.blc ранее записанных наборов параметров. Прочитанные наборы параметров добавляются в конец списка. При совпадении названий программа добавляет в конце вставляемых названий соответствующее число, чтобы обеспечить уникальность названий наборов параметров в пределах файла блочной модели.
- чтение из файла с расширением *.blc ранее записанных наборов параметров. Прочитанные наборы параметров добавляются в конец списка. При совпадении названий программа добавляет в конце вставляемых названий соответствующее число, чтобы обеспечить уникальность названий наборов параметров в пределах файла блочной модели.
![]() - запись в файл *.blc всех наборов параметров из списка.
- запись в файл *.blc всех наборов параметров из списка.
![]() - переместить текущий набор параметров вверх в списке.
- переместить текущий набор параметров вверх в списке.
![]() - переместить текущий набор параметров вниз в списке.
- переместить текущий набор параметров вниз в списке.
![]() - производится проверка текущего набора параметров.
- производится проверка текущего набора параметров.
Если в процессе проверки обнаруживается ошибка, то выводится сообщение об этом. Например :
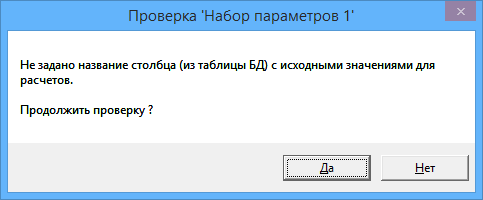
Можно либо продолжить проверку, чтобы программа сообщила обо всех ошибках в текущем наборе параметров (ответить "Да"), либо перейти к исправлению параметров (ответить "Нет").
Если в активных (отмеченных как используемые для расчетов) наборах параметров будут ошибки, то при попытке начать построение модели программа сообщит, в каких наборах параметров имеются ошибки и не начнет построение модели до тех пор, пока все ошибки не будут исправлены.
НАСТРОЙКИ ДЛЯ ТЕКУЩЕГО НАБОРА ПАРАМЕТРОВ
Таблица БД, из которой брать исходные значения и координаты - из таблиц, имеющихся в БД, название которой задано на вкладке "Ввод/вывод" рассматриваемого диалога, выбирается таблица, из которой будут браться исходные точки с содержаниями для построения модели.
Если в проект не загружено ни одной БД или на вкладке "Ввод/вывод" не задан файл БД, то список таблиц будет пустым.
В качестве исходной может быть использована любая таблица БД, но чаще всего для построения модели используется таблица с интервалами одинаковой или примерно одинаковой длины.
Для получения подобных интервалов можно использовать расчетную таблицу, в которой формируются композиты по горизонтам и/или композиты фиксированной длины.
Для разных наборов параметров можно использовать разные таблицы, но только из одного и того же файла БД, заданного на вкладке "Ввод/вывод".
Доп. условия (формула) для выбора интервалов из таблицы БД:
В тех случаях, когда требуется использовать не все интервалы из таблицы БД, а только их часть, то задается формула, по которой производится выбор проб, используемых для расчета блочной модели.
Формула либо непосредственно записывается в управляющий элемент, либо, что более удобно, формируется в диалоге "Формула для расчета",вызываемом при нажатии на кнопку Построение формулы... .
Допустим, в расчетах по текущему набору параметров необходимо использовать только пробы, относящиеся к окисленной части месторождения и в таблице БД имеется столбец "Окисление", в котором для интервалов из окисленной части месторождения записано "OXIDE". Если задать формулу [Окисление] == "OXIDE" , то для расчета будут выбраны только те интервалы, которые относятся к зоне окисления.
Если, к примеру, необходимо произвести расчет с использованием не всех разведочных выработок, а только тех, которые были пройдены на определенном этапе разведке, то при помощи соответствующей формулы (и наличии соответствующей информации об этапах разведки в БД) можно легко произвести соответствующую выборку выработок.
Для метода обратных расстояний задаются следующие 2 параметра: - степень и сглаживающий параметр. Подробнее - см. описание метода обратных расстояний.
СТОЛБЦЫ ТАБЛИЦЫ БД
С ИСХОДНЫМИ ЗНАЧЕНИЯМИ ДЛЯ РАСЧЕТОВ - этот столбец обязательно должен быть задан, т.к. именно из него берутся исходные данные для расчетов.
Для метода обратных расстояний этот столбец должен быть числовым или спецтекстом (спецтексты при расчете преобразуются в числа).
Для метода ближайшего соседа этот столбец также может быть и текстовым.
Столбец должен присутствовать в заданной выше таблице БД.
С коэффициентом, корректирующим вес пробы - необязательный столбец, в котором для каждого исходного интервала задается коэффициент, на который умножается весовой коэффициент, используемый при оценке содержания.
Например, это может быть коэффициент, учитывающий разный объемный вес.
Если имеется несколько коэффициентов, которые необходимо использовать при расчетах, то предварительно все эти коэффициенты перемножаются и записываются в отдельный столбец таблицы БД, который и подается на вход построения блочной модели.
Перемножение столбцов в таблице БД легко выполнить при помощи расчетных формул.
Столбец должен присутствовать в заданной выше таблице БД.
СТОЛБЦЫ БЛОЧНОЙ МОДЕЛИ (при отсутствии - будут созданы автоматически)
Задаются названия столбцов блочной модели, в которые будут записываться результаты расчетов.
Если каких-либо из этих столбцов нет в блочной модели, то они будут автоматически добавлены.
ДЛЯ ЗАПИСИ ВЫЧИСЛЕННЫХ ЗНАЧЕНИЙ - обязательный столбец, в который записывается результат вычисления (оценки содержания в блоке/субблоке блочной модели).
Если столбец отсутствует в блочной модели и создается новый, то ему присваивается такой тип данных, который соответствует типу данных столбца с исходными данными из таблицы БД.
Это может быть либо дробное число, либо текст, причем текст может быть только в случае использования метода ближайшего соседа.
Для записи количества проб, участвовавших в оценке блока - необязательный столбец, служащий для записи информации о количестве проб, использованных при оценке блока.
Если столбец отсутствует в блочной модели и создается новый, то он будет иметь тип - "Дробное число 4 байта".
Для записи количества выработок, участвовавших в оценке блока - необязательный столбец, служащий для записи информации о количестве выработок, использованных при оценке блока.
Если столбец отсутствует в блочной модели и создается новый, то он будет иметь тип - "Целое число (2 байта). От 0 до 65528.".
Для записи номера эллипсоида выбора (вложенные эллипсоиды) - необязательный столбец, служащий для записи информации о номере эллипсоида, использованного при расчетах.
Основной эллипсоид (самый маленький) имеет номер 0.
Если используются дополнительные (расширенные) эллипсоиды, то они имеют номера от 1 до 4.
Если столбец отсутствует в блочной модели и создается новый, то он будет иметь тип - "Целое число(1 байт). От -128 до +120".
Если создавать столбец вручную, то желательно делать его таким, чтобы могли записываться не только положительные, но и отрицательные числа, так как если ни в один эллипсоид не попало достаточное количество проб, то вместо номера эллипсоида выбора будет записано значение -1.
Для записи [приведенного] расстояния до ближайшей пробы - необязательный столбец, служащий для записи информации о расстоянии до ближайшей пробы из проб, использованных в расчетах.
Если столбец отсутствует в блочной модели и создается новый, то он будет иметь тип - "Дробное число 8 байт".
Для записи дисперсии - необязательный столбец, служащий для записи информации о дисперсии, вычисленной по пробам, использованным в расчетах.
Если столбец отсутствует в блочной модели и создается новый, то он будет иметь тип - "Дробное число 8 байт".
Создание новых блоков блочной модели / использование существующих :
Оценка содержания может быть произведена только для тех блоков/субблоков (в пределах параллелепипида блочной модели), для которых в поисковый эллипсоид попадает достаточное количество проб.
Исходная блочная модель может быть :
а). совсем пустой, т.е. не содержать ни одного блока;
б). частично заполненной - часть параллелепипеда блочной модели заполнена блоками/субблоками, а оставшаяся часть - пустая;
в). полностью заполненной - весь параллелепипед блочной модели заполнен блоками/субблоками.
В пустых частях блочной модели могут быть созданы новые блоки или субблоки.
Субблоки создаются только в пределах того блока, который уже частично заполнен ранее созданными субблоками, иначе создается новый блока (базового размера).
Результаты расчетов могут записываться и в существующие блоки/субблоки.
Новые - если отмечено, то производится создание новых блоков/субблоков в тех точках, где в поисковый эллипсоид попадает достаточное количество проб и нет существующих блоков / субблоков.
Если базовый блок является частично пустым, т.е. частично заполнен существующими субблоками, то новые субблоки создаются только в той части базового блока, в которой нет существующих субблоков.
Если не отмечено, то новые блоки/субблоки не создаются.
Существующие - если отмечено, то производится запись результатов расчета в те существующие блоки/субблоки, для которых в поисковый эллипсоид попадает достаточное количество проб.
Обработка существующих блоков/субблоков при недостатке проб для оценки (когда записывать нечего)
Оставлять имеющиеся значения без изменений - существующие блоки/субблоки не изменяются.
Записывать значение по умолчанию, заданное для столбца (чаще всего пустое значение или ноль) - в существующий блок/субблоки записываются значения по умолчанию, заданное для каждого из записываемых столбцов. Значение по умолчанию имеется у каждого столбца блочной модели и может быть изменено пользователем. В том случае, когда на начало расчета столбец не существовал, а создавался программой непосредственно перед расчетом, значением по умолчанеию у такого столбца будет пустое значение.
Обработку производить только для существующих блоков модели с учетом принадлежности к домену (зоне):
Нередко требуется произвести вычисления не для всех блоков блочной модели, а только для некоторых из них, в соответствии со значением, записанном в заданном столбце (для удобства будем называть это принадлежностью к некоторой зоне).
Естественно, что проверку записанного значения можно произвести только для существующих блоков/субблоков и существующего столбца в блочной модели, а новые столбцы не создаются из-за того, что для них не может быть известна принадлежность к зоне.
Столбец блочной модели, в котором записана принадлежность к домену - задается существующий столбец блочной модели, в котором записана принадлежность к тому или иному домену (зоне).
Этот столбец может быть как числовым, так и текстовым.
Столбец таблицы БД, в котором записана принадлежность к домену (1) - задается существующий столбец из таблицы БД, в котором, как и в заданном столбце блочной модели, записана принадлежность к домену (зоне).
Если столбец БД задан, то для расчета содержания в блоке используются только те интервалы (композиты), которые содержат то же самое значение, что и в столбце блочной модели для этого блока.
Например, если для блока (субблока) блочной модели записано "РТ 5", то для расчета содержания в этом блоке (субблоке) будут использованы только те интервалы (композиты), у которых в заданном столбце также записано "РТ 5".
Столбец таблицы БД, в котором записана принадлежность к домену (2) - второй столбец из таблицы БД, в котором записана принадлежность интервала опробования (композита) к домену.
Например, если для блока (субблока) блочной модели записано "РТ 5", то для расчета содержания в этом блоке (субблоке) будут использованы только те интервалы (композиты), у которых записано "РТ 5" либо в первом, либо во втором из заданных столбцов в таблице БД.
Запись вести в блоки, имеющие (в столбце зоны) следующее значение - если блок/субблок блочной модели содержит в столбце Столбец блочной модели, в котором записана принадлежность к зоне значение, равное заданному, то блок используется для расчетов. Все остальные блоки - пропускаются.
Обычно этот параметр используется в том случае если не задается предыдущий параметр, хотя запрета на одновременное использование этих двух параметров нет.
Если при использовании рассматриваемого параметра требуется выбрать лишь часть проб из таблицы БД, то разумнее использовать описанные выше Доп. условия (формула) для выбора интервалов из таблицы БД.
Количество точек дискретизации по осям
Для получения более сглаженной оценки содержания в блоке иногда используется вычисление содержаний в нескольких точках (называемых точками дискретизации), расположенных в базовом блоке так, что они являются центрами одинаковых по размеру блочков.
По каждой из осей блочной модели задается количество точек дискретизации.
При вычислениях для каждого базового блока блочной модели производится вычисление содержания в каждой точке дискретизации, а итоговое содержание в базовом блоке получается как среднее арифметическое из полученных в точках дискретизации значений.
При вычислении содержания для субблоков возможны 2 варианта:
1. Среднее содержание вычисляется так же, как и для базового блока и присваивается всем субблокам -если отмечен элемент диалога Для субблоков использовать среднее по всем точкам дискретизации.
2. Для каждого субблока находится средневзвешенное значение содержания исходя из кусочков субблока, попадающих в параллелепипеды, обрамляющие точки дискретизации - если не отмечен элемент диалога Для субблоков использовать среднее по всем точкам дискретизации.
При использовании точек дискретизации возникает вопрос - какие пробы использовать для вычислении в каждой из точек дискретизации ?
С одной стороны, вроде бы логично помещать эллипсоид выбора в каждую из точек дискретизации. Но в таком случае возникают проблемы, связанные с тем, что в некоторых точках дискретизации в эллипсоид попадет недостаточное для расчетов количество проб.
В некоторых программах выбор проб отдельно для каждой из точек дискретизации приводит к появлению блоков, содержания в которых вычислены по небольшому количеству точек дискретизации или даже по одной точки дискретизации, в то время как эллипсоид, помещенный в другие точки дискретизации, а также точку центра блока, не содержит достаточного количества проб. В результате такая блочная модель обычно содержит большее количество блоков, чем блочная модель, построенная только по точкам, попадающим в эллипсоид, помещенный в точку центра базового блока. Причем характерным является "расширение" блочной модели именно по краям, когда имеет место недостаток информации.
В DIGIMINE точки дискретизации используются только для расчетов (т.к. изменяются расстояния от точек дискретизации до проб), а выбор проб для каждого базового блока производится однократно - для эллипсоида, помещенного в точку центра базового блока.
Дополнительная информация для лучшего понимания получаемого результата.
1. При выполнении расчетов по каждому из активных наборов параметров производится перебор всех возможных базовых блоков блочной модели (если создание новых блоков не задано, то 'пустые' блоки пропускаются).
2. Для каждого базового блока вычисляется одно или несколько значений (по количеству точек дискретизации) заданного параметра (обычно содержания).
Вычисляемое значение (обычно содержание) для базового блока вычисляется по всем полученным в точках дискретизации значениям, а по субблокам - в зависимости от параметра Для субблоков использовать среднее по всем точкам дискретизации.
3. Что происходит, когда задано создание новых блоков ?
3а. Если базовый блок, по которому вычислено значение, пустой, то в блочную модель добавляется новый базовый блок.
3б. Если базовый блок пустой, но значение не вычислено (не хватило проб), то ничего не происходит, новый блок в модель не добавляется.
3в. Если базовый блок, по которому вычислено значение, частично пустой, а частично заполнен существующими субблоками, то в пустой части этого базового блока будут созданы новые субблоки и в них записаны соответствующие вычисленные значения.
Если при этом задана обработка существующих блоков, то в существующие субблоки этого базового блока будут записаны вычисленные значения, е если обработка существующих блоков не задана, то существующие субблоки этого блока останутся без изменений.
4. Что происходит, когда задана обработка существующих блоков ?
4а. Если вычисления для базового блока выполнены, то производится запись соответствующих значений в базовый блок или в субблоки этого базового блока.
4б. Если вычисления для базового блока не выполнены (не хватило проб), то содержимое базового блока (или субблоков этого блока) либо не изменяется, либо в них записывается значение по умолчанию, в зависимости от соответствующего параметра. Значение по умолчанию имеется у каждого столбца блочной модели и может быть изменено пользователем. В том случае, когда на начало расчета столбец не существовал, а создавался программой непосредственно перед расчетом, значением по умолчанеию у такого столбца будет пустое значение.