В текстовом файле, предназначенном для импорта блочной модели должны присутствовать 6 обязательных "столбцов" - координаты центров блоков и размеры блоков по каждой из трех координатных осей. Кроме этих столбцов возможно наличие произвольного количество других столбцов.
Каждая строка текстового файла (за исключением строк заголовка) должна соответствовать одному блоку или субблоку блочной модели.
Для импорта блочной модели из текстового файла необходимо выбрать пункт меню "Файл/Импорт/ Блочной модели (blo) из текстового файла... ".
Далее производится выбор, в соответствующем диалоге, текстового файла на диске, в котором находится информация о блочной модели, после чего появляется диалог "Импорт блочной модели из текстового файла":
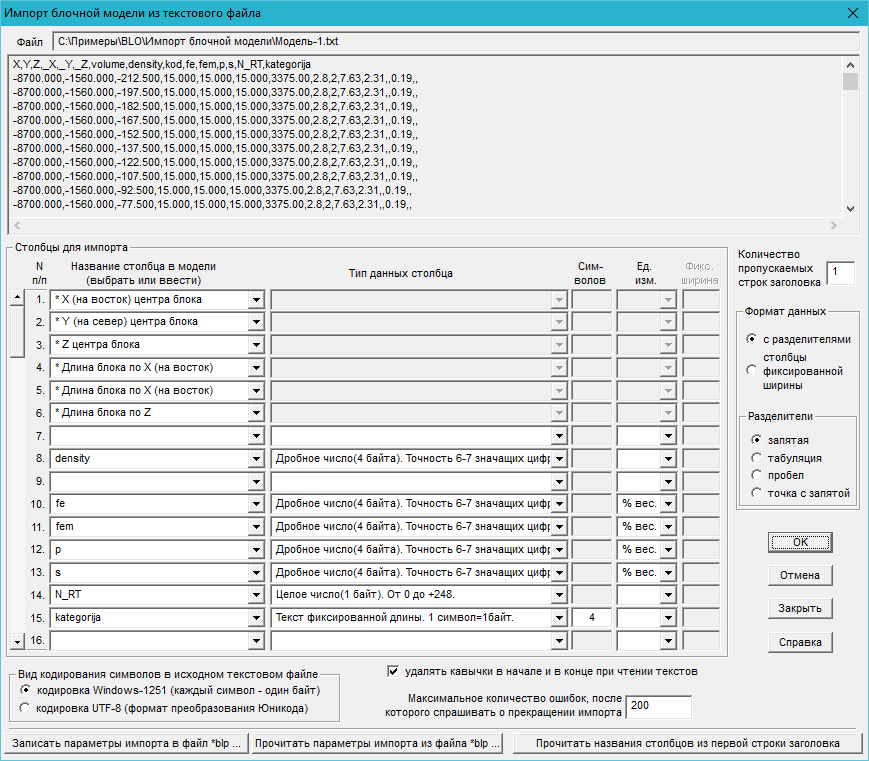
В верхней части диалога выводится информация о названии исходного текстового файла, а также несколько сотен начальных строк из этого файла.
Столбцы для импорта - задается информация об импортируемых столбцах. Столбцы перечисляются в том порядке, в котором они располагаются в исходном текстовом файле. Если какие-либо столбцы не требуется импортировать, оставляется пустое место. В том случае, когда количество столбцов превышает количество столбцов, помещающихся в диалоге, производится "прокрутка" списка при помощи соответствующей линейки прокрутки, располагающейся в левой части диалога.
Название столбца модели (выбрать или ввести) - названия обязательных столбцов (координаты центра и размеры блоков) выбираются из выпадающего списка, названия остальных столбцов вводятся пользователем.
Тип данных столбца - для столбцов, не являющихся обязательными, задается тип данных (формат хранения в блочной модели). Допускаются числа - дробные или целые, а также тексты фиксированной длины:

Для дробных чисел чаще всего используются 4-байтовые числа.
Для целых чисел формат выбирается в зависимости от минимального и максимального значений чисел, которые будут храниться в столбце.
Символов - для столбцов с текстами задается максимальное количество символов в столбце.
Ед. изм. - задаются единицы измерения. Единицы измерения необходимы для правильных вычислений при подсчете запасов. Для объемного веса единицы измерения не задаются (а если заданы, то при расчетах игнорируются), т.к. всегда считается, что объемный вес задан в т/м3.
Единицы измерения для столбцов блочной модели можно задать/изменить и при последующей работе с моделью.
Фикс. ширина - в том случае, когда в исходном файле информация записана в столбцах фиксированной ширины, для каждого импортируемого (а также и для каждого пропускаемого) столбца задается количество символов, занимаемое столбцом в исходном файле:
Количество пропускаемых строк заголовка – задается количество пропускаемых строк в начале файла, в которых записана некоторая служебная информация, чаще всего - описание столбцов.
Формат данных
В исходном файле столбцы могут либо иметь переменное количество символов (с разделителями), либо фиксированное количество символов для каждого столбца (столбцы фиксированной ширины).
В случае исходных данных с разделителями, указывается разделитель информации из разных столбцов, которым может быть , , или . Если в исходных данных идут два разделителя подряд, считается что вводится "пустое" значение.
Вид кодировки символов в исходном текстовом файле
Символы в текстовых файлах могут кодироваться разными способами.
В настоящее время наиболее распространенными для русского языка являются следующие 2 способа кодирования:
1. Кодировка Windows-1251, в которой каждый символ занимает один байт.
2. Кодировка UTF-8. Латинские символы, а также основные служебные символы записываются при помощи одного байта каждый. Символы кириллицы записываются при помощи двух байтов, а для некоторых "экзотических" символов требуются три или более байтов.
Удалять кавычки в начале и в конце при чтении текстов - если отмечено, то в тех случаях, когда в исходном файле текстовые значения заключены в кавычки, производится удаление этих кавычек.
Максимальное количество ошибок, после которого спрашивать о прекращении импорта - после встречи заданного количества ошибок программа выдаст следующее сообщение:
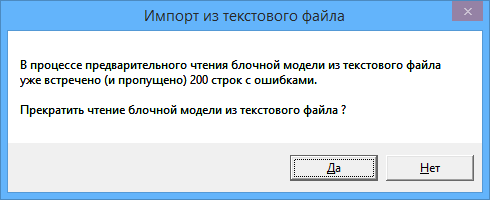
Подобное сообщение позволяет сэкономить время в случае очень большого количества ошибок, которое может появиться, например, если пользователь перепутает столбцы или формат данных в столбцах.
Если ответить "Нет", то максимальное количество ошибок будет увеличено вдвое и ввод будет продолжен.
Записать параметры импорта в файл *.blp - параметры импорта, заданные в рассматриваемом диалоге, записываются в файл с расширением blp.
Прочитать параметры импорта из файла *.blp - параметры импорта берутся из ранее записанного файла с расширением blp.
Прочитать названия столбцов из первой строки заголовка - программа производит попытку прочитать названия столбцов из первой строки заголовка и занести их в соответствующие элементы диалога.
Для приведенного выше примера импорта это приведет к следующему результату:
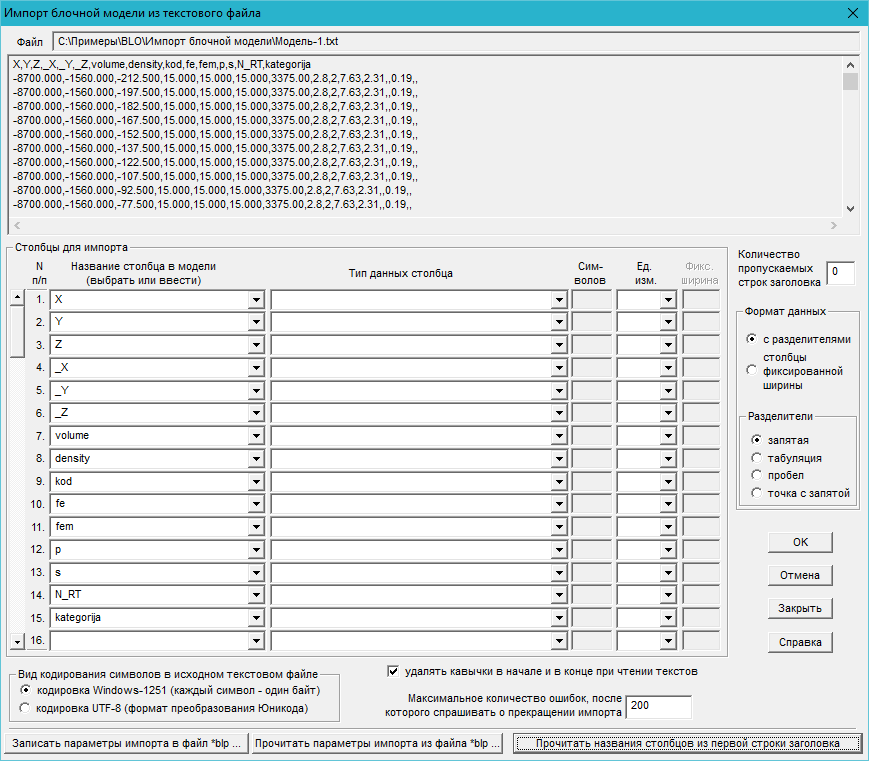
Вместо столбцов X, Y, Z, _X, _Y, _Z необходимо выбрать соответствующие обязательные столбцы, т.к. по названию столбца в заголовке нельзя сделать однозначный вывод о том, что же там записано.
Далее настраиваются, как описано выше, форматы столбцов.
При нажатия кнопки ОК в рассматриваемом диалоге, будет начата предварительная обработка исходного файла.
Основная цель предварительной обработки - получить информацию о размерах блоков, имеющихся в модели, а также о минимальных и максимальных координатах блоков (в конечном итоге интересуют не центры блоков, а "углы" блоков).
После предварительной обработки появится диалог "Параметры импортируемой блочной модели":
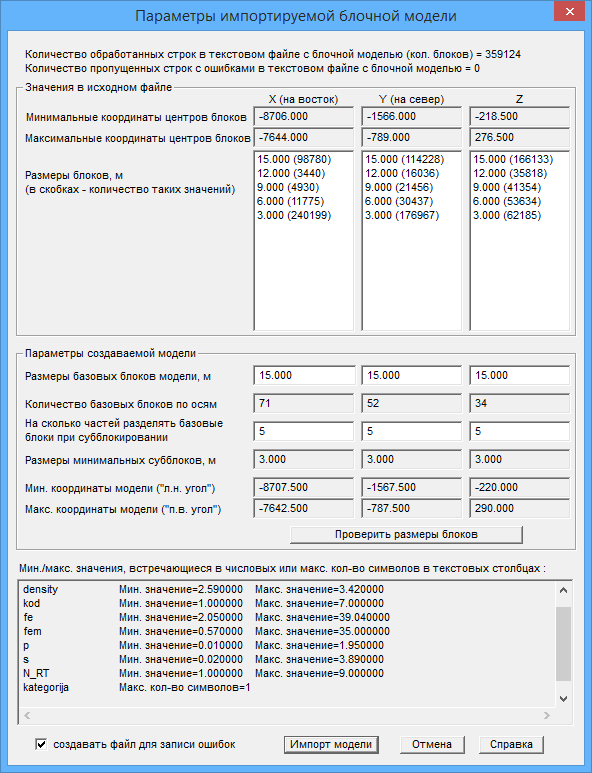
Значения в исходном файле
Количество обработанных строк в текстовом файле с блочной моделью (кол. блоков)= - выводится количество строк с информацией (без пропущенных строк заголовка), в которых не найдено ошибок, т.е. потенциальное количество блоков.
Количество пропущенных строк с ошибками в текстовом файле с блочной моделью= - выводится количество строк, в которых обнаружены ошибки на этапе предварительной обработки текстового файла. Информацию о найденных на этапе предварительной обработке ошибках можно посмотреть в окне с информацией о работе программы.
Минимальные (максимальные) координаты центров блоков - выводится информация о минимальных и максимальных координатах центров блоков, встреченных в исходном файле.
Размеры блоков, м (в скобках - количество таких значений) - заполняются списки размеров блоков по каждой из осей, встреченных в процессе предварительной обработки исходного текстового файла.
Если в исходном файле нет ошибок размеров блоков, то верхнее значение, как правило, это размер базового блока, а нижнее - размер минимального субблока.
Размеры (по каждой из осей) импортируемых блоков должны отвечать следующим условиям:
1. Быть кратными размеру минимального субблока.
2. Быть не больше базового блока и не меньше минимального субблока.
Блоки, размеры которых не отвечают этим условиям будут пропущены при импорте.
Параметры создаваемой модели
В диалоге имеется возможность редактирования размеров базового блока и количества частей, на которое разделять базовый блок при субблокировании.
Если в исходном файле нет ошибок размеров блоков, то обычно нет необходимости изменять эти параметры. Более подробно об их редактировании - см. ниже.
На основании информации, прочитанной из исходного файла, а также заданных размеров базового блока и количества частей, на которые разделять базовый блок при субблокировании, программа выводит информацию о количестве базовых блоков, размерах минимальных субблоков, минимальных и максимальных координатах модели.
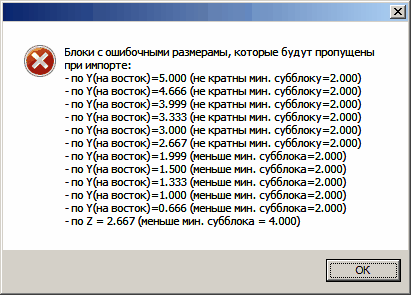
Проверить размеры блоков - при нажатии на эту кнопку производится проверка размеров блоков. В случае обнаружения ошибок выдается сообщение, подобное следующему:
Мин./макс. значения, встречающиеся в числовых или макс. кол-во символов в текстовых столбцах
В процессе предварительной обработки исходного файла программа производит подсчет минимальных и максимальных значений в числовых столбцах, а также максимального количества символов, встретившихся в текстовых столбцах.
Эта информация может оказать помощь в оптимизации памяти, отводимой под каждый из столбцов.
Для примера, приведенного на картинках выше, можно отметить, что в столбце kategorija встретилось не более одного символа, в то время как для этого столбца предварительно было отведено памяти под 4 символа.
Чтобы изменить количество символов для столбца kategorija, необходимо вернуться в первый диалог, для чего нажать кнопку в диалоге Параметры импортируемой блочной модели.
Создавать файл для записи ошибок - если этот элемент отмечен, то информация об ошибках будет записана в текстовый файл, имеющий название, состоящее из названия исходного файла для импорта и добавленного к нему текста "(ошибки импорта)" (например, "Модель-1(ошибки импорта).txt"). Файл записывается в тот же раздел, в котором находится исходный файл для импорта.
Если рассматриваемый элемент не отмечен, то информация об ошибках будет выведена во вспомогательное окно с информацией о работе программы.
Импорт модели - нажатие на эту кнопку запускает процесс импорта модели.
Информация о результатах импорта будет выведена в окне для сообщений, а также записана в окно с информацией о работе программы.
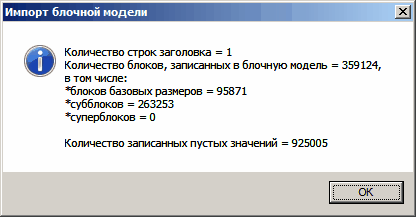
Обратим внимание на то, что в блочной модели допускаются пустые значения в столбцах, не являющихся обязательными. При наличии пустых значений программа выводит информацию о количестве записанных в модель пустых значений вместе с информацией о результатах импорта, чтобы привлечь внимание пользователя к факту наличия пустых значений в блочной модели.
После импорта будет создана и добавлена в проект новая блочная модель с названием как у исходного файла для импорта с добавлением к нему текста "(импорт)" и расширением blo (например, "Модель-1(импорт).blo"). На данном этапе запись на диск не производится и модель существует только в оперативной памяти. После проверки корректности полученной модели пользователь может записать файл на диск.
Также будет создано окно с таблицей блочной модели.
Об изменении размеров базового блока и минимального субблока
Иногда в исходном файле встречаются ошибки размеров блоков. Тогда необходимо проанализировать имеющиеся размеры блоков и, по возможности, откорректировать размер базового блока и размер минимального субблока (изменяя количество субблоков).
Например, при импорте блочной модели были получены следующие размеры блоков в исходном файле (по каждой из осей) :
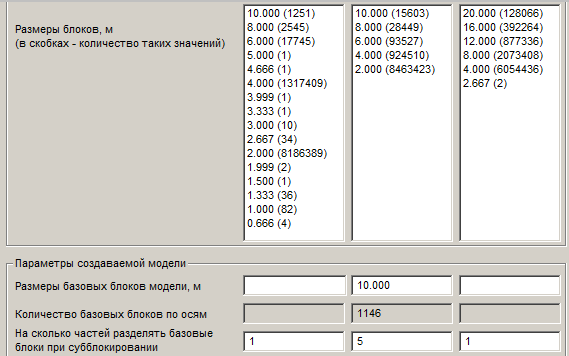
Имеются проблемы с определением размеров минимального субблока по оси X (на восток) и оси Z, поэтому программа не предлагает по этим осям размеры базового блока и количество частей при субблокировании. Следовательно, без ввода этих значений вручную, импорт производиться не будет.
Можно предположить, что по оси X размер минимального субблока должен быть 1м или2м. В первом случае при импорте будут пропущены блоки с размерами 4.666м, 3.999м, 3.333м, 2.667м, 1.999м, 1.5м, 1.333м и 0.666м. Общее количество пропускаемых блоков - 81 блок. Во втором случае дополнительно будут пропущены еще 93 блока с размерами 5.000м, 3.000м и 1.000м. Общее количество блоков (записей) в исходном файле - 9 525 512.
По оси Z явно ошибочными являются 2 блока с размерами 2.667м.
Зададим размер базового блока по оси Y 10м, по оси Z 20м, количество субблоков : по оси Y - 5 (размер минимального субблока будет 2м), по оси Z - также 5 (размер минимального субблока будет 4м).
При таких параметрах импорт возможен, хотя и с потерей некоторого количества исходных блоков.
В дополнение отметим, что задаваемые размеры базового блока должны присутствовать в списке с размерами блоков.
Размеры минимального субблока могут отличаться от размеров, имеющихся в списке, например, быть меньше минимального размера субблока.