После выбора пункта меню "Файл/Импорт из текстового файла/Заголовков выработок..." программа запрашивает имя текстового файла, в каждой строчке которого записана информация по одной выработке. Расширение файла может быть любым. После выбора текстового файла появляется следующий диалог, в котором задаются параметры импорта в таблицу со списком выработок:
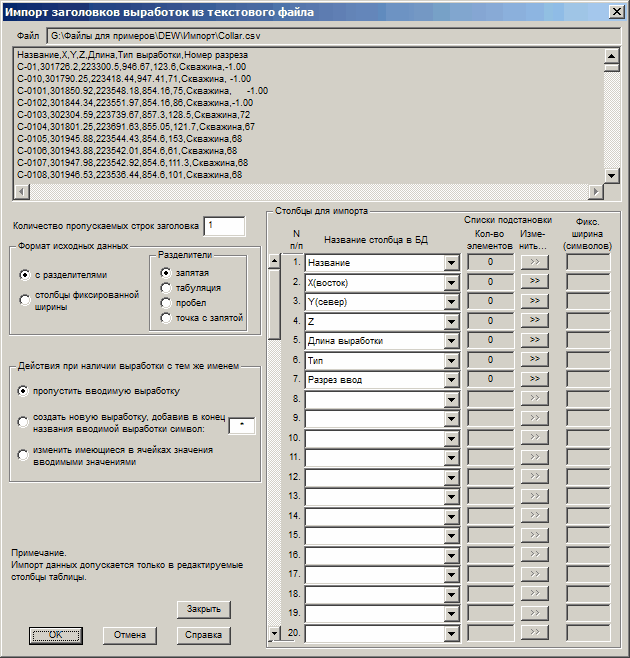
Файл. – Имя открытого текстового файла для импорта. Ниже следуют начальные строки из этого файла (не весь файл!). Ориентируясь на содержимое первых строк, пользователь может контролировать структуру исходной информации в файле.
Количество пропускаемых строк заголовка – задается количество пропускаемых строк в начале файла, в которых записана некоторая служебная информация, чаще всего - описание столбцов.
Формат исходных данных.
В исходном файле столбцы могут либо иметь переменное количество символов (с разделителями), либо фиксированное количество символов для каждого столбца (столбцы фиксированной ширины).
В случае исходных данных с разделителями, указывается разделитель информации из разных столбцов, которым может быть , , или . Обратите внимание, что использование в качестве разделителя символа корректно только в том случае, когда пробелы точно отсутствуют внутри исходных данных. По-возможности, пробел в качестве разделителя лучше не использовать.
Если в исходных данных идут два разделителя подряд, считается что вводится "пустое" значение.
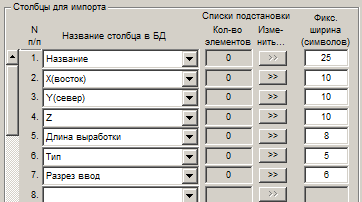
В случае исходных данных со столбцами фиксированной ширины для каждого импортируемого столбца задается количество символов, занимаемое столбцом в исходном файле:
В тех случаях, когда название выработки в импортируемой строке совпадает с названием выработки, уже имеющейся в базе данных, возможны несколько вариантов обработки, задаваемых в группе элементов Действия при наличии выработки с тем же именем:
Пропустить вводимую выработку – если при импорте информации встретится выработка с именем, которое уже использовано в БД, импортируемая строка пропускается, имеющаяся в БД выработка не изменяется.
Создать новую выработку, добавив в конец названия символ … - в конец названия импортируемой выработки добавляется заданный символ (по умолчанию – '' ) и делается попытка импорта выработки с модифицированным названием. Если и это название в БД уже использовано, в конец добавляется еще один заданный символ, до тех пор, пока не сформируется название, отличное от названий, имеющихся в БД. Если в процессе добавления символов в конец названия получается недопустимо длинное название (в случае, когда столбец с названием имеет формат "Текст фиксированной длины"), импортируемая строка пропускается.
Изменить имеющиеся в ячейках значения вводимыми значениями – производится ввод импортируемых значений в имеющуюся выработку. Те столбцы имеющейся выработки, которые не участвуют в импорте, остаются без изменений.
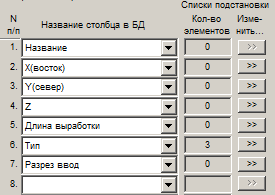
Столбцы для импорта
№ п/п – порядковый номер столбца в исходном текстовом файле.
Название столбца в БД – из выпадающих списков выбираются названия столбцов в базе данных, в которые будет производиться запись импортируемой информации.
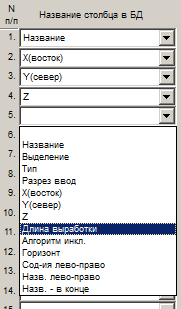
В выпадающих списках присутствуют только редактируемые столбцы, то есть те, в которые может производиться ввод информации. Нередактируемые столбцы, в том числе те, которые пользователь задал временно нередактируемыми, в списке отсутствуют. Первым элементом списков является пустая строка, которая используется в том случае, когда в исходном файле есть столбцы, которые не требуется импортировать. Например, если в исходном текстовом файле 5-й столбец нужно пропустить, то в строке с № п/п, равным 5, задается пустое значение.
В том случае, когда максимальный номер импортируемого столбца превышает 20 (количество строк с названиями столбцов, одновременно отображаемых в диалоге), можно произвести прокрутку строк, используя линейку прокрутки, расположенную слева от порядковых номеров столбцов.
Списки подстановки
В некоторых случаях имеется необходимость выполнения замен некоторых значений, имеющихся в исходном текстовом файле, на другие значения.
Например, если в исходном текстовом файле пустые значения в каком-либо столбце заданы значением -1.0, а пользователю необходимо, чтобы вводились не минус единицы, а именно пустые значения.
Или, скажем, типы выработок в исходном текстовом файле записаны как целые числа, а пользователю необходимо, чтобы тип выработки, заданный числом, был преобразован в текст. Пример с типом выработок примечателен еще и тем, что по умолчанию во вновь создаваемой базе данных столбец с типом выработки задается именно как текст (хотя, при желании, может быть изменен), причем для данного столбца задан список допустимых значений (который тоже может быть изменен).
Подстановка может оказаться полезной и в том случае, если имеется потребность в замене некоторых нечисловых значений в числовые.
Для того чтобы задать автоматическую подстановку значений, используются кнопки ![]() , расположенные справа от названий импортируемых столбцов.
, расположенные справа от названий импортируемых столбцов.
При нажатии на такую кнопку появляется диалог "Список подстановки для столбца", в котором производится редактирование элементов списка подстановки для определенного столбца.
Для тех столбцов, для которых заданы списки подстановки, справа от названия столбца будет ненулевое значение Кол-во элементов. Например, если для столбца Тип задано 3 элемента подстановки, то будет записано число 3. Нулевые значения для остальных столбцов указывают на то, что для них списки подстановки не заданы.
Отметим, что в программе DigiMine имеются некоторые специальные возможности, позволяющие в ряде случаев обойтись без списков подстановки при импорте. Особо отметим возможность создания столбцов с типом данных "Спецтекст фиксированной длины для дробных чисел" и " Спецтекст фиксированной длины для целых чисел". В таких столбцах, предназначенных, в основном, для хранения числовых значений, могут записываться также и некоторые (задаваемые в диалоге "Параметры столбца") текстовые значения. Например, "", "", "", "" и т.п.
![]() При формировании базы данных, как правило, лучше вводить исходную информацию в том виде, в каком она имеется в первоисточнике. А преобразование текстовых значений в числовые производить в процессе вычислений, что и предусмотрено в столбцах с типом данных "Спецтекст…".
При формировании базы данных, как правило, лучше вводить исходную информацию в том виде, в каком она имеется в первоисточнике. А преобразование текстовых значений в числовые производить в процессе вычислений, что и предусмотрено в столбцах с типом данных "Спецтекст…".
После того, как в диалоге "Импорт заголовков выработок из текстового файла" произведено заполнение описанных выше элементов диалога, можно начать процесс импорта нажатием на кнопку ОК.
Если будет нажата кнопка "Закрыть", то процесс импорта не будет осуществляться, но будут запомнены (в оперативной памяти, а после записи БД на диск - и на диске) все настройки диалога для таблицы со списком выработок.
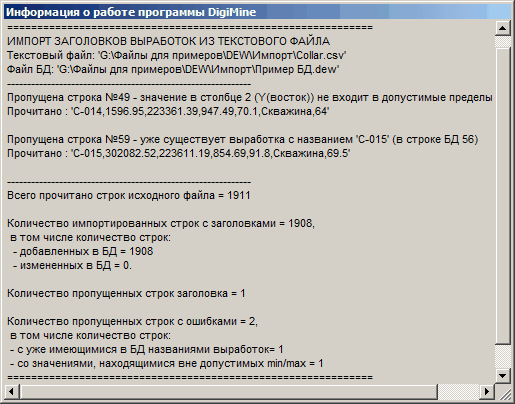
В процессе импорта информации из текстового файла в таблицу с заголовками выработок выполняются ряд проверок, предохраняющих базу данных от некорректной информации. В тех случаях, когда программа обнаруживает ошибку, производится запись информации об ошибке в окно с информацией о работе программы, ошибочная строка пропускается. После завершения обработки исходного текстового файла выводится информация о результатах импорта, количестве импортированных и количестве пропущенных строк.
В том случае, когда пользователя не устраивает результат импорта, можно отменить все операции, выполненные в процессе импорта, нажатием на кнопку ![]() в графическом меню.
в графическом меню.
![]() Обратите внимание на то, что минимальные и максимальные допустимые значения (либо списки допустимых значений) для столбцов таблицы БД необходимо задать до начала импорта, чтобы в процессе импорта производились соответствующие проверки, позволяющие избежать грубых ошибок.
Обратите внимание на то, что минимальные и максимальные допустимые значения (либо списки допустимых значений) для столбцов таблицы БД необходимо задать до начала импорта, чтобы в процессе импорта производились соответствующие проверки, позволяющие избежать грубых ошибок.